This post is part of a nine post series about the SOLID principles and code architecture. You can check all the posts here:
- Software Architecture in Game Development
- The Single Responsibility Principle
- The Open Closed Principle
- The Liskov Substitution Principle
- Conceptual Meaning Of Interfaces
- The Interface Segregation Principle
- The Dependency Inversion Principle
- SOLID: How to use it, Why and When
- SOLID For Unity Monobehaviours
Introduction: What is the Interface Segregation Principle
The Interface Segregation Principle, deals with the problem of types that can do different things. Some classes although they represent a single entity that represents something, can do things that conceptually can be grouped into different interfaces.
For example a Character class can have methods for moving the character, methods that are responsible for making the character attack and methods responsible for dealing with the damage the character takes when it is being attacked.
We may be tempted for such a class, to create an interface ICharacter that has all the public methods the Character class will need to implement. But this is wrong. As I mentioned in my previous post Conceptual meaning of Interfaces an interface conceptually belongs to the class or system that is using it, not the class that implements it.
Depending on the systems we have, the ISP tells us to split the interface into two or more interfaces, that have only the methods that those systems need.
Knowledge of only what you need
Let’s suppose that we have a system that is responsible for movement, a system that is responsible for attacks and some systems that deal damage. For example in a game, the characters, either the player character or the enemies, may not be the only entities that can take damage. A door can take damage by hits or a tree by fire.
Anything that deals damage, doesn’t need to know what the entity that takes damage represents. It only needs to know what the entity can do. The same is true for the systems that are responsible for creating movement and attacks.
Even if in our game only the characters can take damage, that need is still true. The system that is dealing damage doesn’t need to depend on methods that is never going to use, like the methods that are responsible for movement.
An example that uses the ISP
Let’s suppose that the ICharacter interface is like this:
public interface ICharacter
{
void MoveUp();
void MoveDown();
void MoveRight();
void MoveLeft();
void ApplyDamage();
void OnDeath();
void Attack();
void GetTarget();
}
This is a violation of the ISP.
We have two different ways to deal with that, so that our code conforms to the ISP. In both of those, the first thing we have to do is to split the ICharacter interface into three interfaces:
public interface IMovable
{
void MoveUp();
void MoveDown();
void MoveRight();
void MoveLeft();
}
public interface IAttack
{
void Attack();
void GetTarget();
}
public interface IDamageable
{
void ApplyDamage();
void OnDeath();
}
The less common way, that also adds more complexity to our code is with composition.
Our Character class, can have an IMovable field that creates an object that implements the IMovable interface. This object will have a reference to the Character class and will act as an adapter. Each of the four move methods of the interface will call the corresponding Character methods that will move our character. This way, is not only more complex, but also less performant, as we will have to create a new object each time, of the type IMovable. This solution is useful if the object that we create is needed to act as an adapter, because different classes will have different methods that are responsible for movement differently in our program. For example the player character moves right immediately, but an NPC has to keep moving up until the first junction where it will turn right.
The most common way, that is also the simplest, is that our Character class will implement all those three interfaces directly instead of the ICharacter interface:
public class Character : IMovable, IAttack, IDamageable
{
Like this, the system that is responsible for movement is unaffected by any changes to the interface that has methods it doesn’t use. Any changes won’t have to force recompilation to classes that are inside different assemblies. What we have done visually, is something like this:
From the interface to belong to the assembly that is the class: 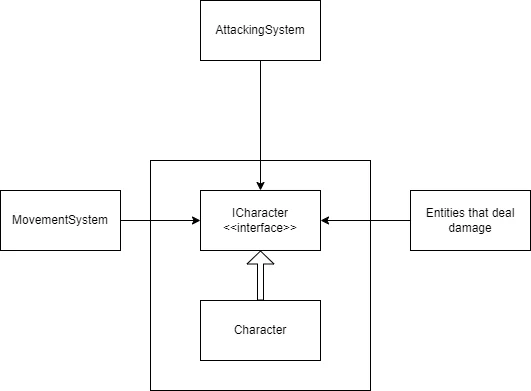
To interfaces that belong to the classes that use them: 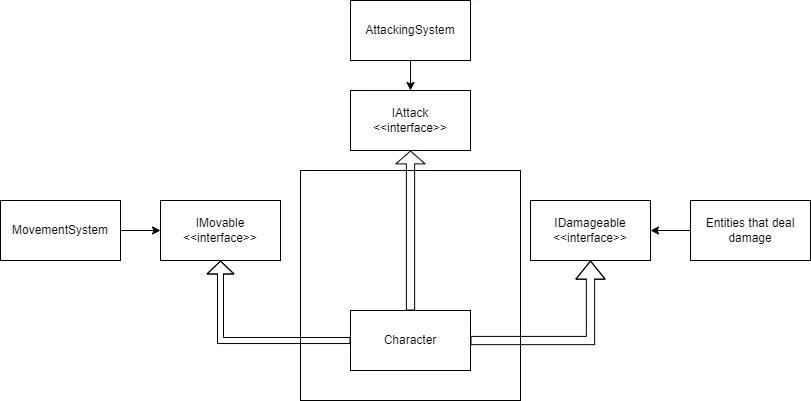
Common Methods and Common Objects
Sometimes we may find ourselves in a situation that a method is needed in two or more interfaces. That’s ok, we can include this method to all the interfaces that need it. If for some reason we find out, that many methods are common to all interfaces, then we have to take a step back and think if those methods should be on their own interface. Conceptually these methods may represent something else, that is not described by the interfaces we have created.
It is not uncommon that a system may need two or more of our interfaces to function. For example, our attacking system may be implemented in such a way, that needs to move the attackers to the proper position with the help of our movement system, before it can begin an attack. There are two solutions to this.
The first is to pass the same object two times. For example if we have a method called InitiateAttack that has two arguments, an IMovable and an IAttack, we can call it like this: InitiateAttack(enemyCharacter, enemyCharacter). This might seem strange, but what we are really doing is not that we are passing the same type twice. For the method, we are passing two different types, an IMovable and an IAttack, even if they are represented with the same object.
Although the first solution is acceptable and is also supported by Bob Martin, many times I have found that the need to pass the same object two or three times, is an indication that I have missed something in my code architecture, so there is a second solution:
Adding a Layer Between Interfaces and the Classes that use them
In the above example, when an enemy character has to pass itself both as an IMovable and as an IAttack to our attacking system, what does that represent?
This actually is an enemy attacker. In the above example of the ISP, the first solution was to create an adapter and use it with composition. The enemy attacker, fits the criteria for such an adapter.
We can implement the Character like this:
public class Character : IDamageable
{
public IMovable Movable { get; }
public IAttack Attacker { get; }
public Character(IMovable movable, IAttack attacker)
{
Movable = movable;
Attacker = attacker;
}
public void ApplyDamage() { }
public void OnDeath() { }
}
Here we comply to the interface segregation through delegation. Then we create the IEnemyAttacker interface and the EnemyAttacker class:
public interface IEnemyAttacker
{
void Attack();
// plus other needed methods here
}
public class EnemyAttacker : IEnemyAttacker
{
private IMovable _movable;
private IAttack _attack;
public EnemyAttacker(IMovable movable, IAttack attack)
{
_movable = movable;
_attack = attack;
}
public void Attack() { }
// plus other needed methods here
}
The important thing here, is that the EnemyAttacker class, acts as an adapter. Whatever methods will be implemented in this class will use the IMovable and IAttack methods to create behavior.
Now, if we have created a character, we can create an enemy attacker whenever that object is needed for our Attack system. For example:
IMovable movable = new Movable();
IAttack attack = new Attacker();
Character character = new Character(movable, attack);
AttackSystem attackSystem = new AttackSystem();
IEnemyAttacker enemyAttacker = new EnemyAttacker(character.Movable, character.Attacker);
attackSystem.InitiateAttack(enemyAttacker);
This is more complicated obviously, but shows the need to create a representation of something when we find ourselves in need to pass the same object to a system two or more times as a different type.
When we find ourselves in situations that we pass the same object as different types, we should pause and think if the combination of these types actually represents something that we haven’t implemented in our code.
Conclusion
As with all the SOLID principles, we should be careful not to over do it with the Interface Segregation Principle. Splitting our interfaces, can save time in the long run, when changes will be needed to the classes that implement those interfaces, but can also add more complexity that is not needed if we never touch those classes again. As I said in my previous post Software Architecture is all about time investment.
In its simplest form, splitting an interface and having a class implement smaller interfaces instead of a big one, can help with our systems. For example, by splitting the ICharacter and having an IMovable interface, we can now add that interface to other classes that can have movement and all those can be controlled by one system that will be responsible for the movement behavior.
Creating adapters that are composed by interfaces can have its uses, but before that, we should weight the pros and cons of this decision: Will the complexity we are adding help us in a way that the changes that will happen in the future to a system will shield the rest of our code from these changes?
In the next post let’s finish the SOLID principles, with the Dependency Inversion principle and the differences with Dependency Inversion. Thank you for reading and as always, if you have any questions or comments you can use the comments section or contact me directly via the contact form or by email. Also if you don’t want to miss any of the new blog posts, you can always subscribe to my newsletter or the RSS feed.